Sidhaarth Sredharan Murali
I'm a Master's student at CMU's School of Computer Science (Fall 2025), focusing on AI Safety, Alignment, and Reinforcement Learning. Over the past year, I’ve transitioned from being new to reinforcement learning to leading hands-on research in RL-based post-training for large language models. I treat research as a sustained effort—dedicating years to making real progress toward solving complex problems rather than just incremental advances.
At CMU, I work closely with faculty across reasoning, exploration, and multi-agent learning:
- I work with Chenyan Xiong on reinforcement learning for agentic search and retrieval, studying how RL-based objectives can improve long-horizon reasoning, tool use, and decision-making in information-seeking agents.
- I work with Katia Sycara on game-theoretic and control-theoretic reinforcement learning for multi-agent systems, exploring how deception and coordination emerge in social deception settings.
- I work with Andrea Zanette on exploratory reinforcement learning, focusing on how exploration strategies interact with safety constraints, sparse rewards, and optimization dynamics.
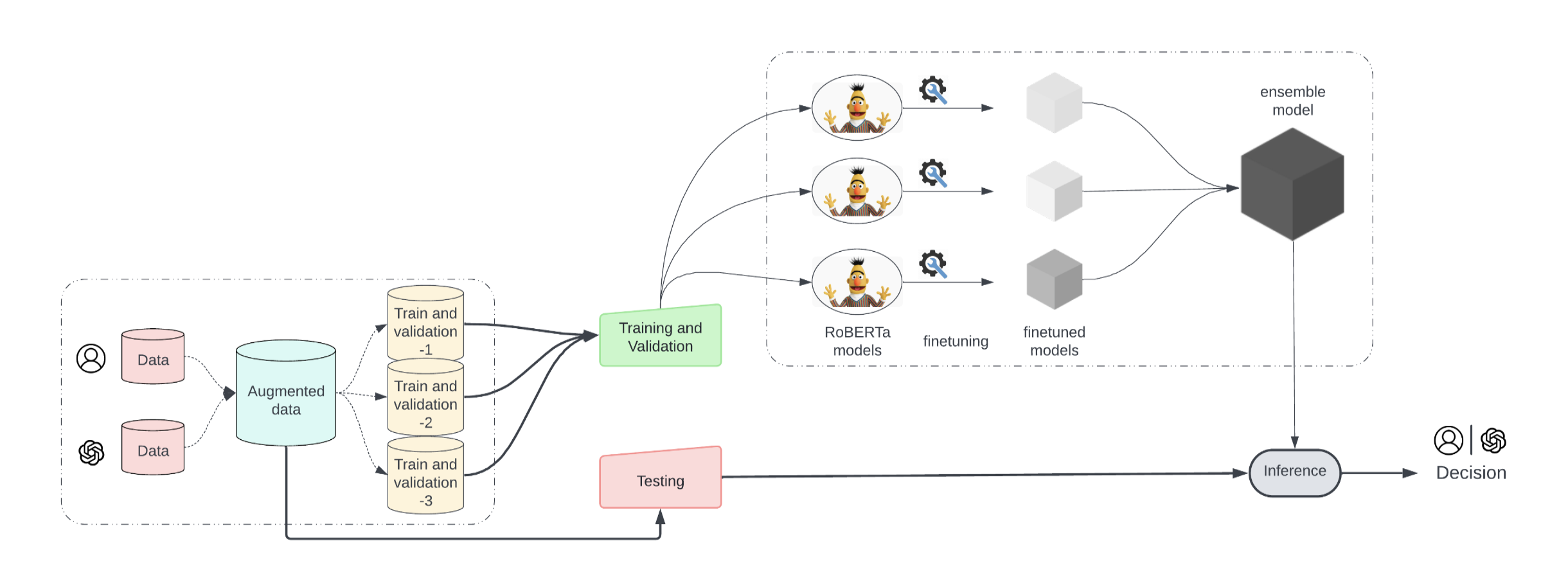
Previously, I developed a bi-level hierarchical RL framework that jointly trains solver models and process reward models, improving reasoning robustness and sample efficiency. This work, matured at CMU, is titled Textual Actor Critic Beyond Training and is currently under submission to ICML 2026.

Industrial Experience
Research
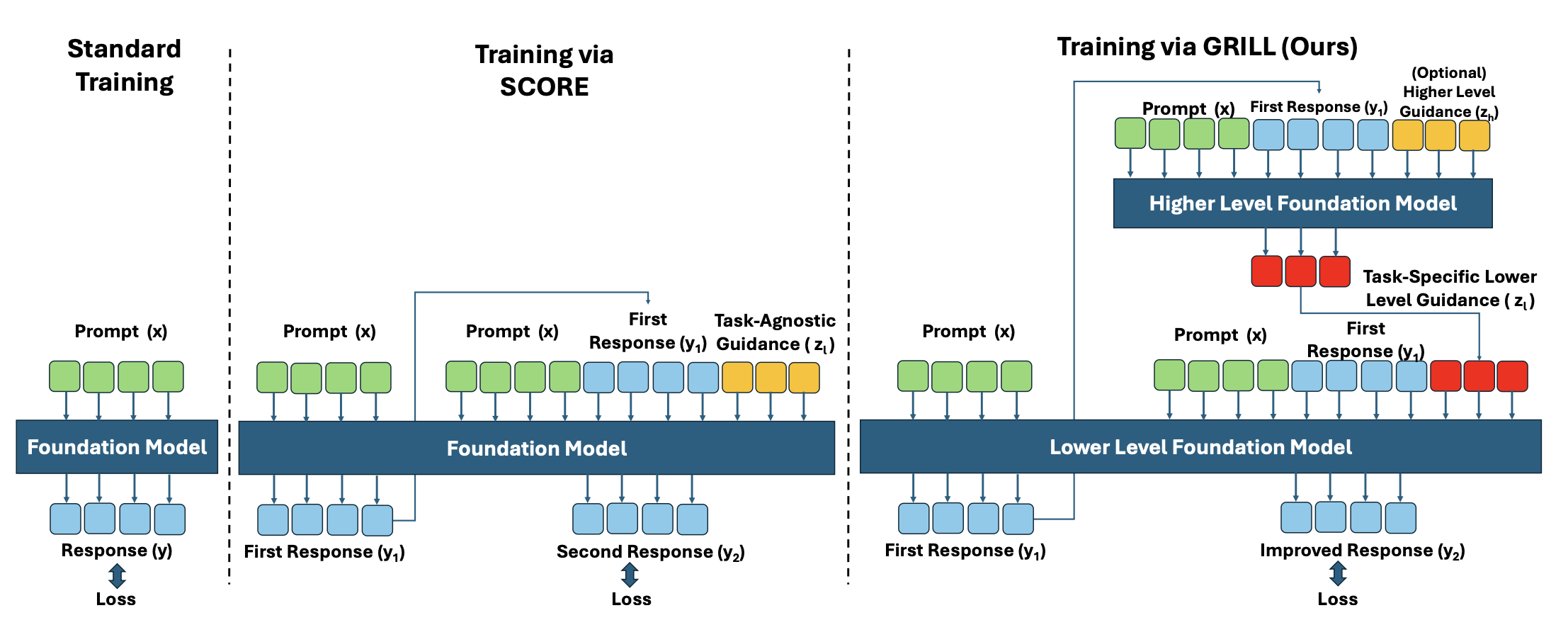
Textual Actor Critic Beyond Training
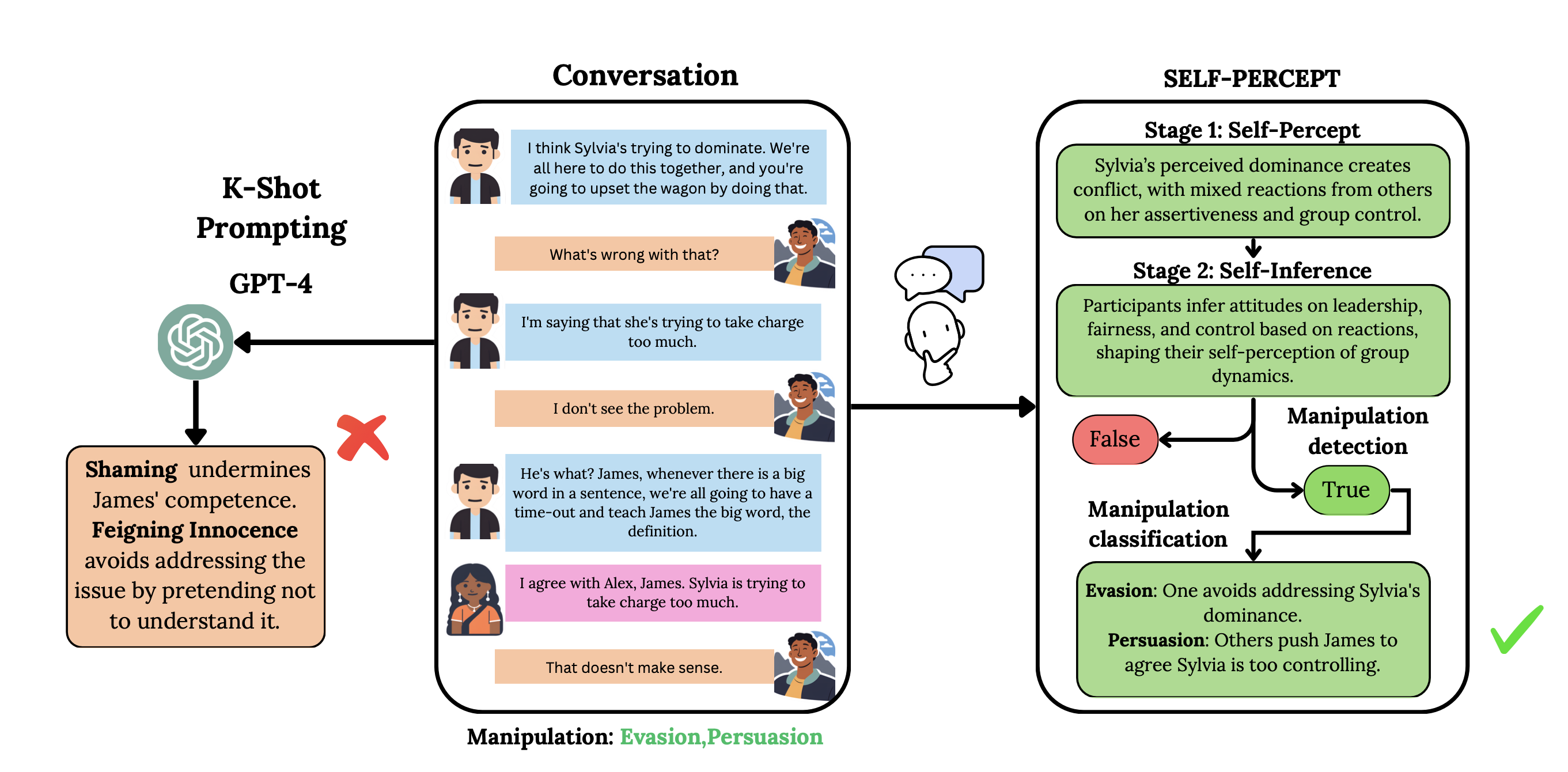
SELF-PERCEPT: Introspection Improves Large Language Models' Detection of Multi-Person Mental Manipulation in Conversations
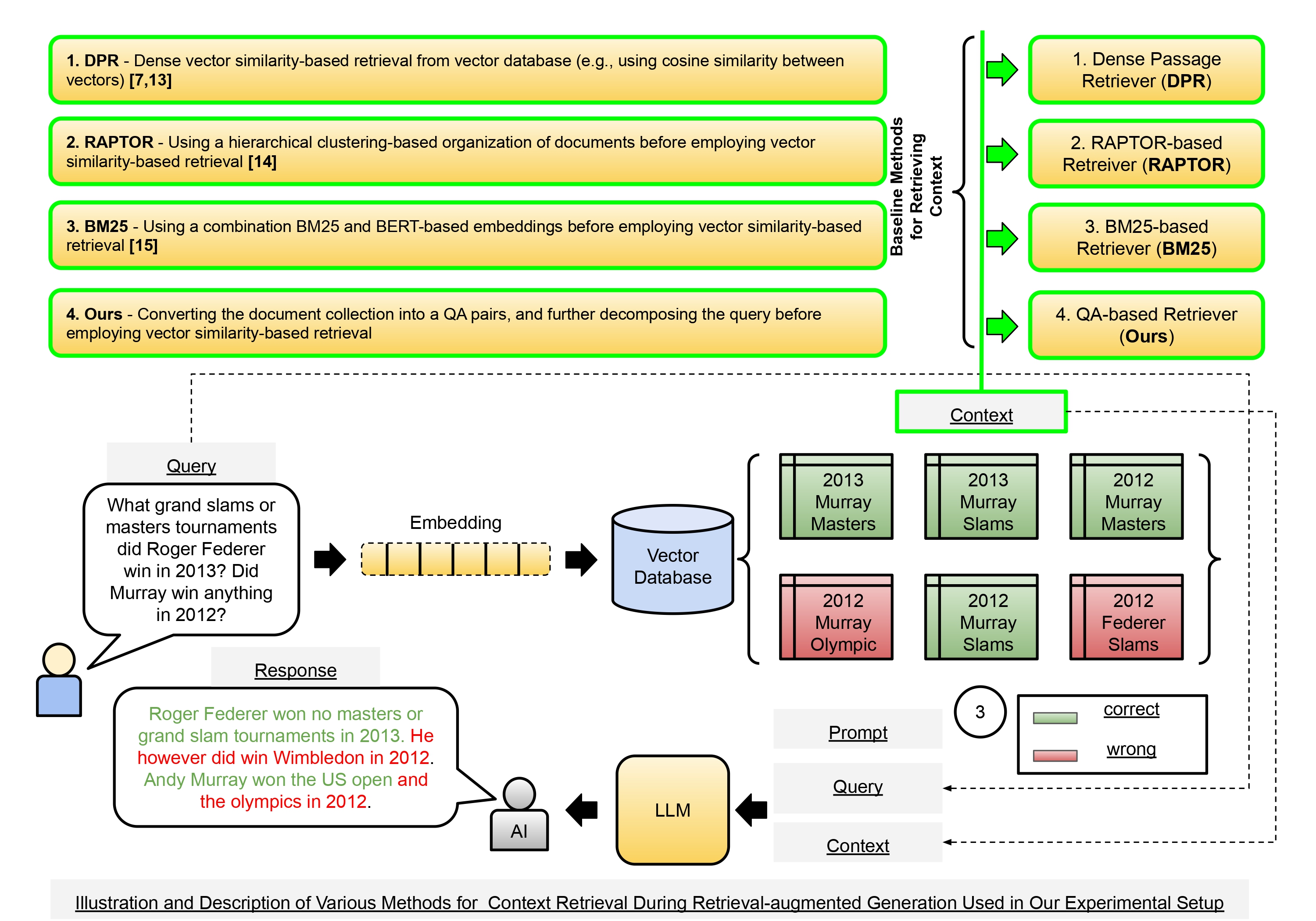
QA-RAG: Leveraging Question and Answer-based Retrieved Chunk Re-Formatting for Improving Response Quality During Retrieval-augmented Generation
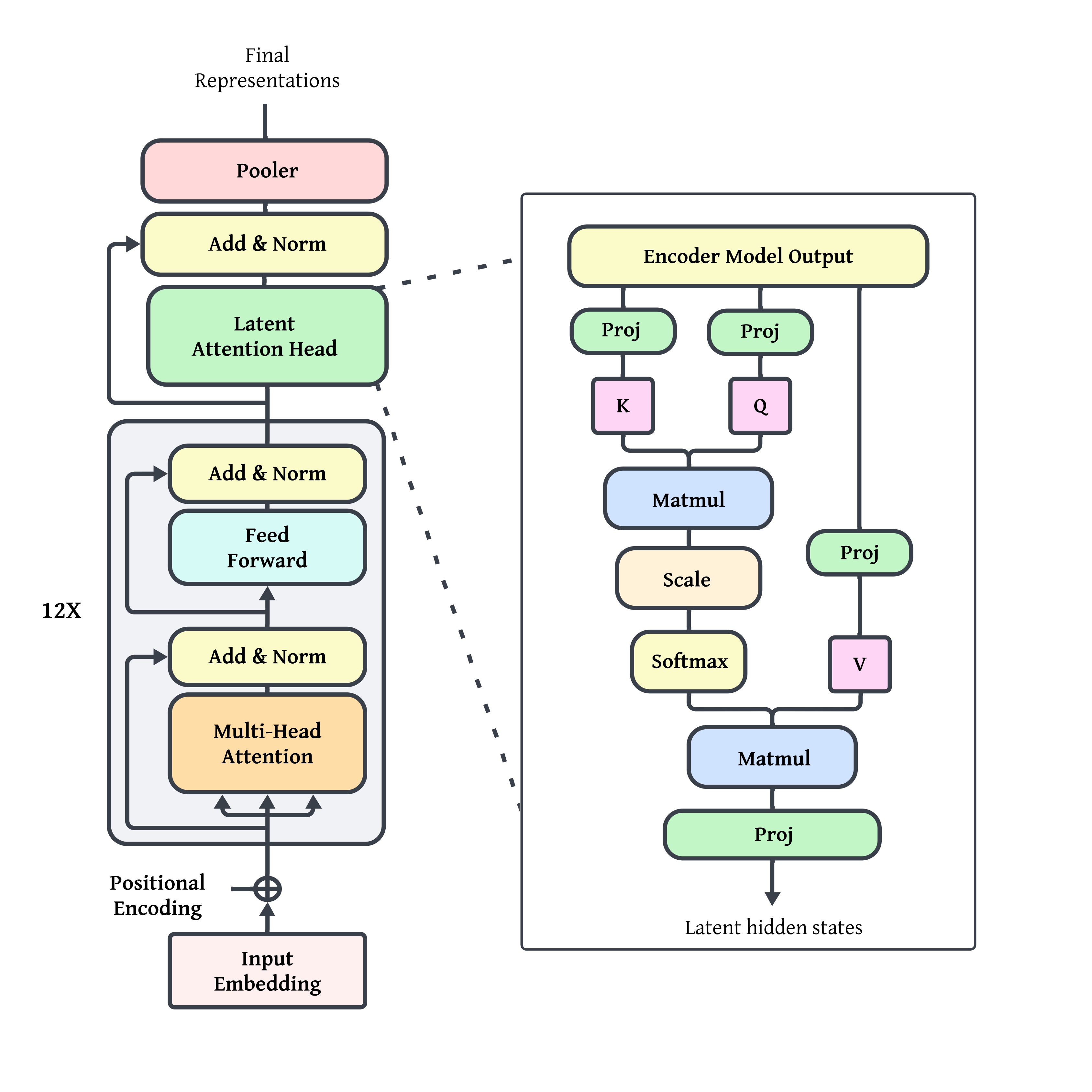
LADDER: Latent Attention and Decomposition for Deep Enhanced Retrieval in Medical Question Answering Systems
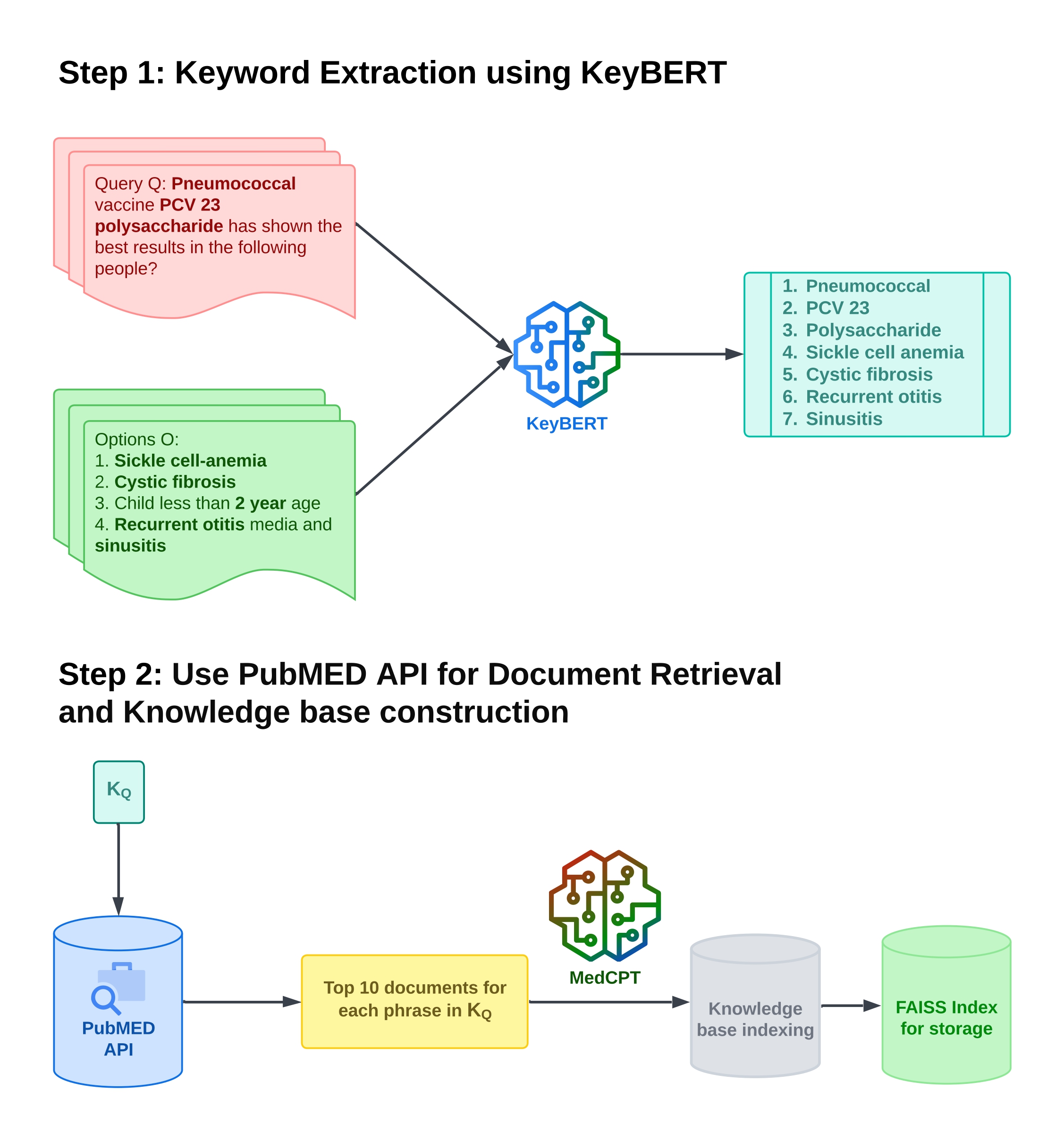
ReMAG-KR: Retrieval and Medically Assisted Generation with Knowledge Reduction for Medical Question Answering
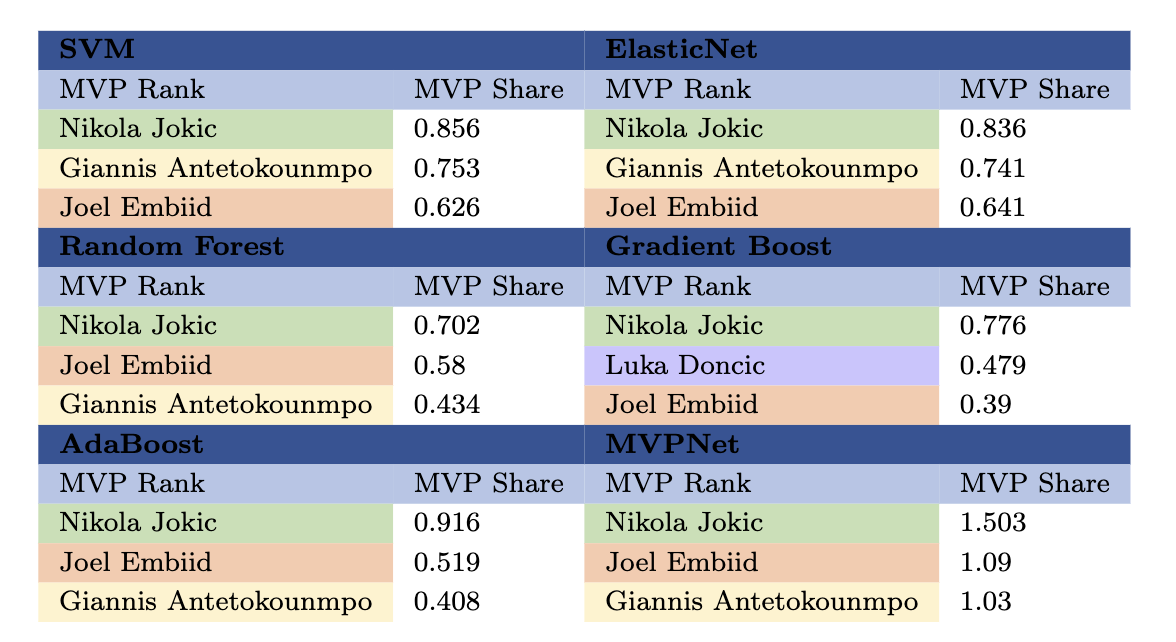
NBA MVP Prediction and Historical Analysis using Cross-Era Comparison Approaches
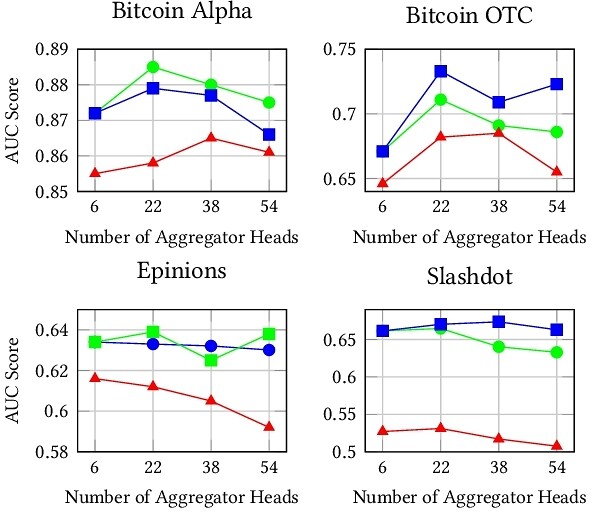
Does Degree Capture It All? A Case Study of Centrality and Clustering in Signed Networks